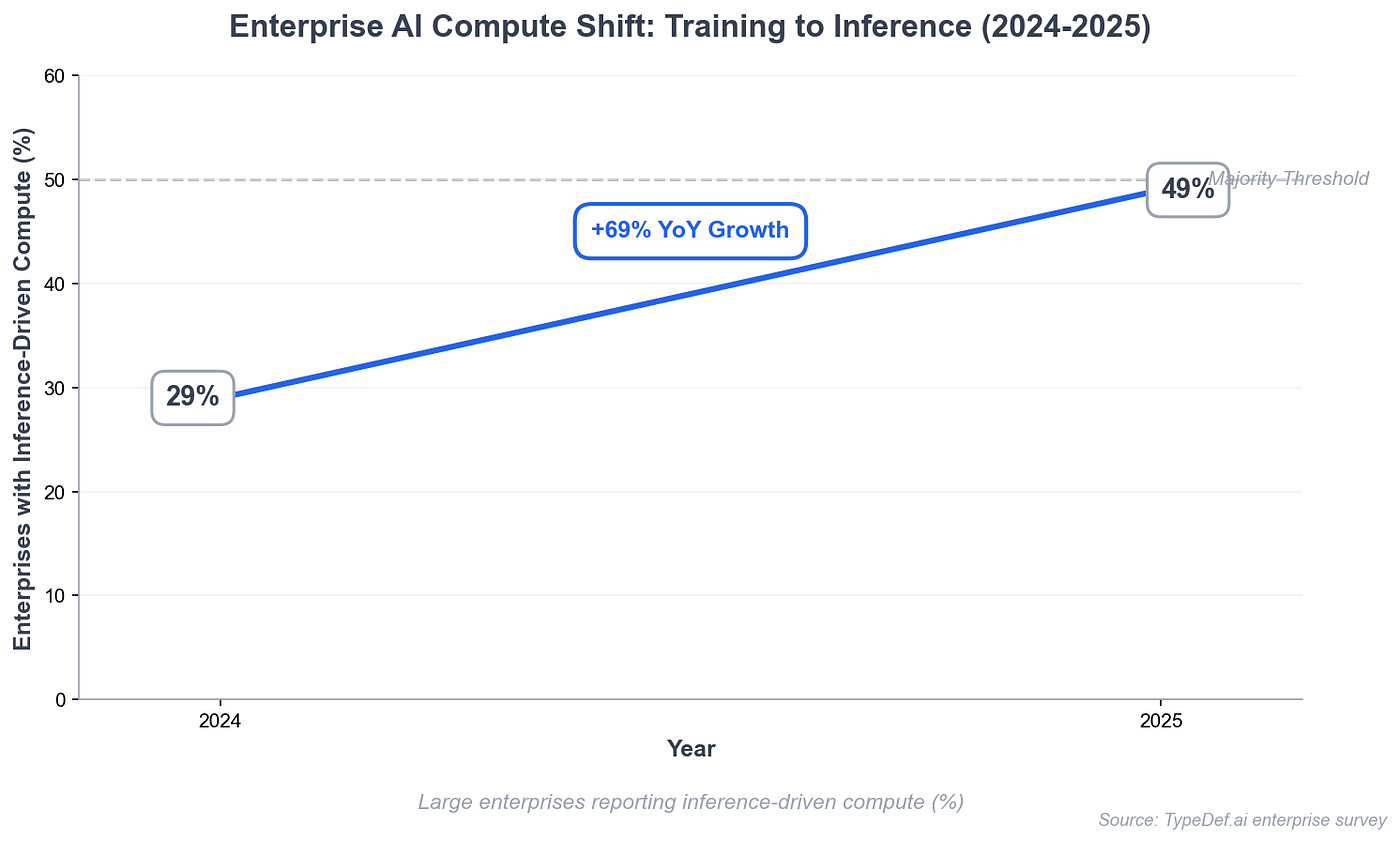
The AI market is still being discussed like a software market, and that framing is already getting old. Software is getting easier to generate, easier to copy, and easier to ship across every category. That changes where pricing power sits, and it changes faster than most people expect. When software starts behaving like a commodity, the durable value shifts toward the engine that powers it. In practical terms, that engine is inference.
This is the core idea behind the inference economy thesis. If software as a service trends toward lower margins, then the main question becomes simple and brutal: who can deliver reliable inference at scale, at low cost, with stable quality, and with credible privacy? The answer to that question will shape the next generation of winners.
Model parity arrives faster than the valuation story suggests.
Most current market narratives still treat frontier model providers as permanent winners. The common argument sounds straightforward and comforting. They have the most capital, the most data centers, and the best models, so they should keep the lead. That argument looks weaker once you study how quickly capabilities spread across the market. The pace of catch-up matters more than the size of the original announcement.
The China angle is important here, even if you disagree about the exact mechanism. Chinese models have been showing up quickly after major releases, often with benchmark performance that looks close enough for many use cases. One explanation is hidden compute investment. Another is stronger distillation and fast engineering cycles. A third is some combination of both forces. The market implication stays the same: model quality parity appears faster than the valuation story usually assumes.
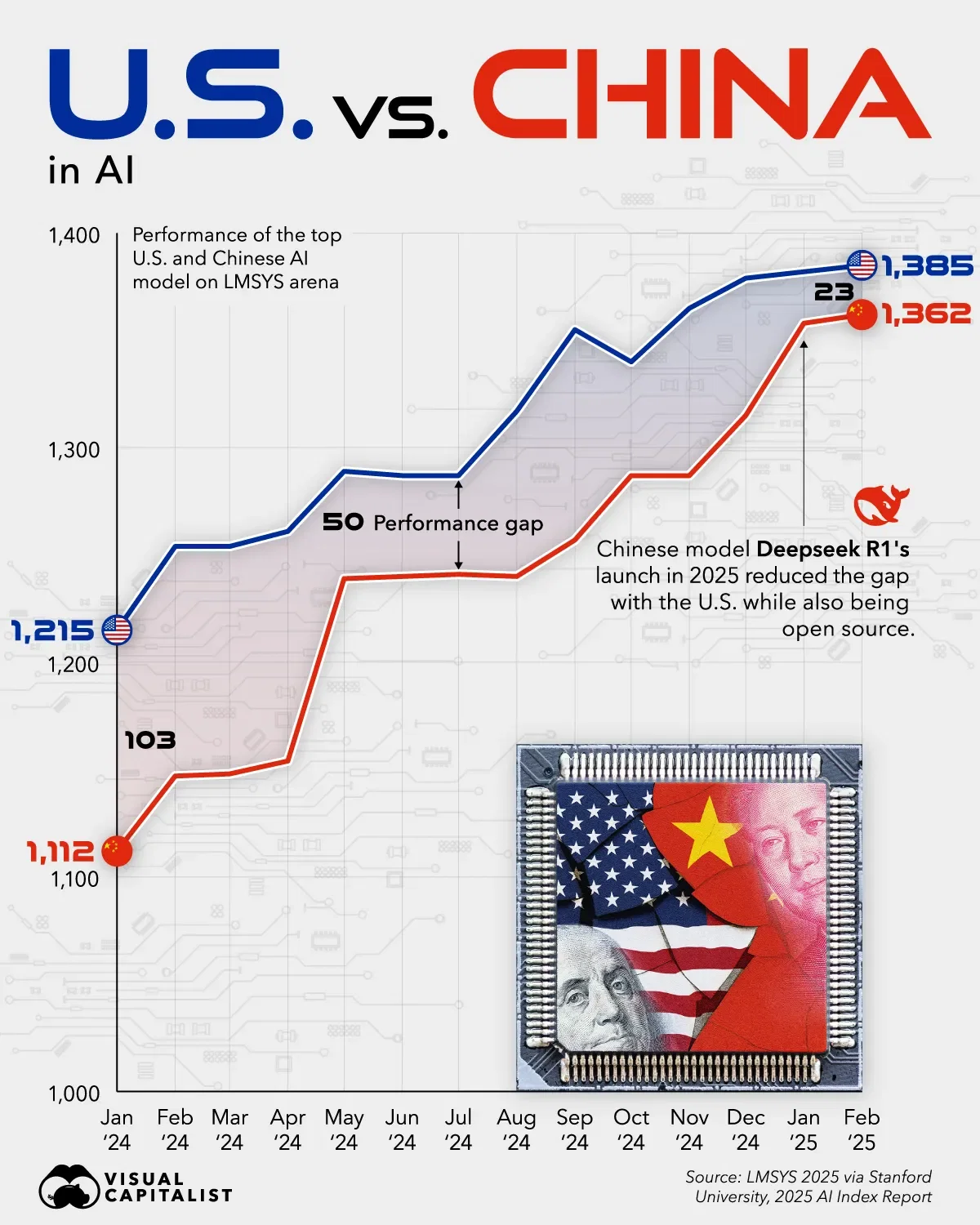
That reality puts pressure on the idea of durable frontier advantage. If comparable output can be reproduced at a much lower cost, the capex narrative starts to wobble. The point is not that frontier labs become irrelevant. The point is that their moat can shrink while demand for AI keeps rising. That combination creates a new kind of market, and that market rewards service quality more than brand mythology.
Inference becomes the real product.
There is also a technical reason why fast catch-up may continue. A growing body of research suggests that large language models converge on similar internal representations of concepts. In plain terms, different models often learn similar maps of meaning after training on large corpora. If that convergence holds, distillation and fine-tuning become more efficient than many people assume. You need fewer brute-force changes when the underlying structure already points in similar directions.
That matters for economics because it reduces the cost of capability transfer. A student model can learn from a teacher model with more targeted adjustments. Those adjustments can be extracted through careful prompting and systematic evaluation of behavior. The process still requires skill, data, and iteration, but the cost curve looks better than a pure from-scratch training story. Once you accept that possibility, the center of gravity moves again. Service reliability, availability, and cost control start looking like the stronger long-term moats.
Hardware economics points in the same direction. Many people speak about compute scarcity as if it will stay permanent and universal. Scarcity will stay real for periods of time, but the market has multiple ways to resolve it. One path is better inference-specific hardware design. Another is spillover when hyperscalers upgrade and liquidate older GPUs. Both paths expand usable capacity outside the largest closed platforms.
Performance per watt is the key pressure inside large data centers. When new hardware delivers much better efficiency, old hardware becomes harder to justify in premium capacity environments. That pushes older GPUs into secondary markets, and those markets broaden access to capable inference hardware. The result is a more distributed supply base for inference, even if the headlines stay focused on frontier clusters.
Once capacity fragments, orchestration is the moat.
Once capacity starts spreading, orchestration becomes the central problem. The market no longer needs only raw chips. The market needs a way to make fragmented compute behave like a professional service. That means stable routing, predictable performance, verification, and quality guarantees. This is exactly where the inference economy thesis becomes useful, because it tells you what the market will pay for next.
There is another pressure building inside enterprise AI adoption. Many companies are buying AI tools as productivity infrastructure, which makes sense in the current cycle. They want faster output, lower labor cost, and better automation across workflows. The invisible part is the strategic knowledge transfer that can happen over time. Workflows, edge cases, prompts, decisions, and domain patterns all become part of a learning loop. The provider improves from that exposure, and the customer pays for the privilege.
Some firms will accept that trade in the early phase because speed matters more than strategic control. Fewer firms will like that trade once alternatives become strong and switching costs become manageable. This is why neutral inference providers matter in the next phase. Companies will want AI capability without feeding a dominant platform that can absorb their operational intelligence. They will want privacy claims that can be checked, not just promised in enterprise contracts. They will want dependable performance without living on a treadmill of silent behavior shifts.
Distributed capacity only matters if it can be turned into a provable service.
This is the practical meaning of an inference economy. The app layer can keep exploding with creativity, and that part will stay exciting. The durable value still accrues to whoever delivers the inference layer with the best combination of trust, quality, and economics. The winning platform may look less glamorous than the winning app, but it will control more of the market logic. It becomes the utility that every product depends on.
That framing clarifies why decentralized compute keeps returning as an important idea. Historically, decentralized compute had a credibility problem. People saw it as unreliable, inconsistent, and hard to verify. Specs looked good on paper, then performance fell apart under real workloads. Inference customers cannot build serious products on that kind of uncertainty. The issue was never just distributed hardware. The issue was converting distributed hardware into a provable service.
That is the gap Ambient is trying to close. The argument is not simply that decentralized compute exists. The stronger argument is that verification can turn fragmented compute into trustworthy inference infrastructure. If a network can prove what work was done, preserve quality standards, and route demand toward reliable providers, then distributed capacity becomes economically useful. At that point, the market no longer sees mystery compute. It sees a service layer that can compete on real terms.
The inference economy thesis is simple once you strip away the noise. Software can become abundant, and applications can become cheaper to build. Inference remains the constant input across all those products. The network that delivers inference with reliability, neutrality, and strong economics will capture durable value. Everything else in this cycle builds on that foundation.